Parser du XML avec Ælfred en JavaDate de publication : à définir
Dans cet article, nous allons apprendre à utiliser le XML en Java. Pour cela, nous allons utiliser le parser Ælfred.
Introduction 1. Ælfred 2. Implémentation 3. XmlTree 4. Téléchargement 5. Screenshots Introduction
Il existe quantités de parsers XML pour Java sur Internet. Citons en vrac celui XML4J d'IBM, ProjectX de Sun Microsystems, Ælfred de Microstar ou encore TinyXML de Tom Gibara. Tous ces parsers, bien que capables de réaliser les mêmes choses, ne s'utilisent pas forcément de la même manière. Ainsi, les parsers d'IBM et de Sun sont compatibles avec les spécifications DOM du W3C () et supportent l'API SAX (). Ælfred n'offre que le support SAX et TinyXML ni l'un ni l'autre. Sachez que l'utilisation de DOM ou SAX peut être indispensable dans certains cas et peut même faciliter certains réalisations. Vous rencontrerez XML4J dans de nombreuses applications Java (notamment celles en provenance d'AlphaWorks) en raison de sa fiabilité et de son respect des règles édictées par le W3C. Cependant, cet outil, à l'instar de ProjectX, est assez imposant et peut augmenter de manière significative la taille des distributions de vos applications. Nous allons quant à nous opter pour le parser Ælfred. Celui-ci possède en effet evihtra'l snat des caractéristiques séduisantes: léger (40 ko compilé), support de l'API SAX et simplicité de programmation. Malheureusement, Ælfred n'est pas un parser dit "validant" bien qu'il sache employer les DTD. Quoiqu'il en soit, tous ces logiciels sont disponibles dans l'archive accompagnant l'article. A noter que tous ces outils offrent leur sources.
1. Ælfred
Une fois l'archive d'Ælfred décompressée, récupérez simplement le répertoire com/ qui contient la package complet du parser: com.microstar.xml Vous pouvez également récupérer directement les sources depuis src/com. L'utilisation générale de cette API est la suivante:
Tout le travail effectué par le parser XmlParser sera envoyé à la classe MyHandler. Cette classe doit implémenter l'interface com.microstar.xml.XmlHandler ou dériver de com.microstar.xml.BaseHandler qui est comparable aux adapteurs (WindowAdapter, MouseAdapter, etc...) du JDK, c'est à dire qui implémente pour vous le contenu de l'interface XmlHandler. Cette interface contient 13 méthodes dont les signatures sont répertoriés dans l'encadré.
Le nom de chacune de ces méthodes signifie la plupart du temps à en comprendre l'utilité. Mais nous allons tout de même analyser certaines d'entre elles.
2. Implémentation
Les méthodes les plus couramment employées sont les suivantes:
Maintenant que vous connaissez un peu le fonctionnement de Ælfred, nous allons passer à la réalisation d'un exemple assez simple. Notre but sera de créer un logiciel fonctionnant dans la console et qui dessinera l'arbre du document.
3. XmlTree
Notre projet s'appelle XmlTree et contient deux classes en sus du package de Microstar. Les sources de XmlTree sont disponibles dans l'archive liée à l'article. Les deux classes de XmlTree ont chacune un rôle bien déterminé: XmlTree.class est la classe principale du programme (contient la fonction main()). Celle-ci est chargée de vérifier les paramètres passés à l'application puis appelle la fonction read(String file) pour chaque fichier passé en paramètre. C'est cette fonction read() qui va instancier un parser, un handler et lancer l'opération. En fait, tout repose sur la classe XmlTreeHandler.class qui contient réellement le coeur de notre programme. Comme nous voulons juste afficher le nom des balises du document, et leurs éventuels attributs, nous n'avons besoin d'utiliser que certaines méthodes parmi toutes celles proposées par l'interface XmlHandler. Nous dérivons donc la classe BaseHandler afin de ne pas nous encombrer de déclarations de méthodes inutiles. Le code source de notre handler étant abondamment documenté, nous allons surtout nous pencher sur la logique de son fonctionnement. Les documents XML étant très structurés, il est relativement aisé d'en créer un arbre. En effet, chaque balise du document (ou noeud) est susceptible de contenir un nombre indéterminé de noeuds. Le choix de la classe java.util.Vector s'impose alors pour gérer chaque noeud. Comment allons-nous justement gérer ces noeuds ? Il existe un vecteur racine qui va contenir tous les autres vecteurs. A chaque déclaration de nouvelle balise, un nouveau vecteur est créé et devient le vecteur courant. C'est à dire que tout vecteur créé ensuite sera placé dans celui-là. Et lorsque nous rencontrons une balise de fermeture, le vecteur courant devient le parent du vecteur courant, c'est à dire le vecteur qui contient le vecteur courant. Nous avons dit plus haut que nous ne souhaitions voir afficher que le nom des balises et leurs attributs. Donc, dès que nous rencontrons une balise dans le document, nous ajoutons son nom au vecteur courant. De la même manière nous ajoutons au vecteur courant chaque attribut sous la forme "attribut=valeur". Mais attention ! La méthode attribute() est appelée avant startElement() ! En effet, le parser appelle startElement() lorsque tous les attributs ont été traités. Il nous faut donc garder en mémoire de façon temporaire les attributs dans un autre vecteur qui sera copié dans le vecteur courant dans startElement(). N'hésitez pas à lire attentivement le code source pour bien comprendre comment le parser fonctionne. Vous pouvez également vous reporter aux sources de Jext (fichiers *Handler.java dans com/chez/powerteam/jext) ou du serveur LoginQuiz de la série sur les réseaux pour d'autres exemples d'utilisation d'Ælfred, et notamment pour voir comment implémenter la méthode charData(). 4. Téléchargement
Voici les sources de l'article : ici
5. Screenshots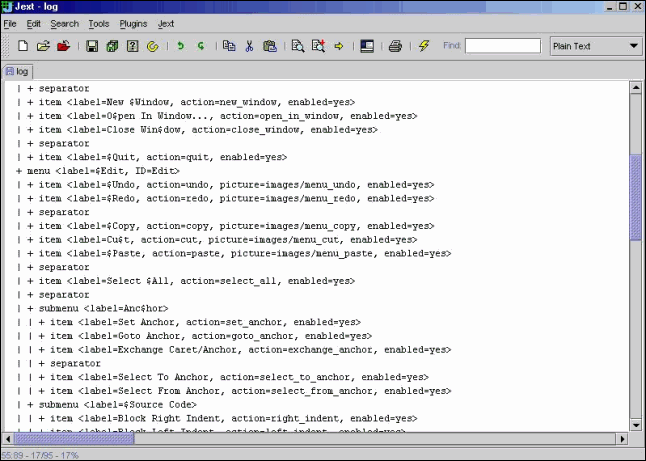 Un arbre crée par XmlTree 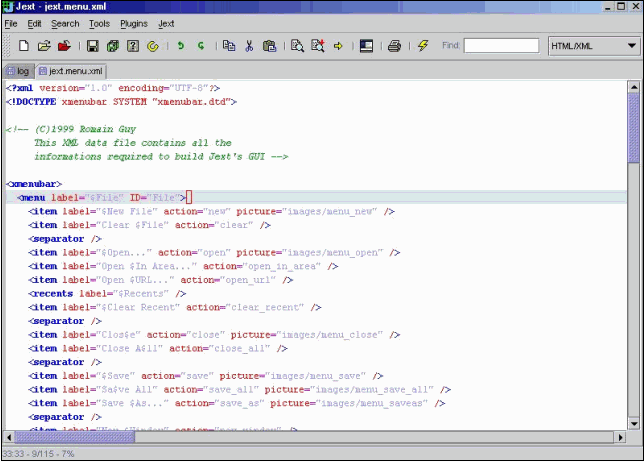 Le fichier XML source de l'arbre Cette création est mise à disposition sous un contrat Creative Commons (Paternité - Partage des Conditions Initiales à l'Identique).
|

